LLM for code generation: a scalable pipeline to gather SFT data

Subscribe to Toloka News
Subscribe to Toloka News
Domain-specific LLMs
Many general-purpose LLMs struggle to perform in specialized areas like law, engineering, coding, or medicine. Therefore numerous companies have started developing domain-specific models optimized for their particular areas of expertise. For instance, there are models like Med-PaLM for medicine and BloombergGPT for finance. In the coding domain, there are also several fine-tuned models such as GitHubCopliot, StarCoder2, and Code Llama. While these current code models are useful for practical tasks, they still have limitations and struggle with more complex problems. A common problem these companies are facing is building high-quality Supervised Fine-Tuning (SFT) datasets that are niche-specific and can be used to fine-tune base LLM models to excel in the desired domain. If you require assistance in gathering domain-specific datasets, Toloka can help. Feel free to reach out to us.
In this article, we will introduce a pipeline that Toloka has developed to collect a high-quality dataset within a coding domain with a throughput of 2000 prompt-completion pairs a month.
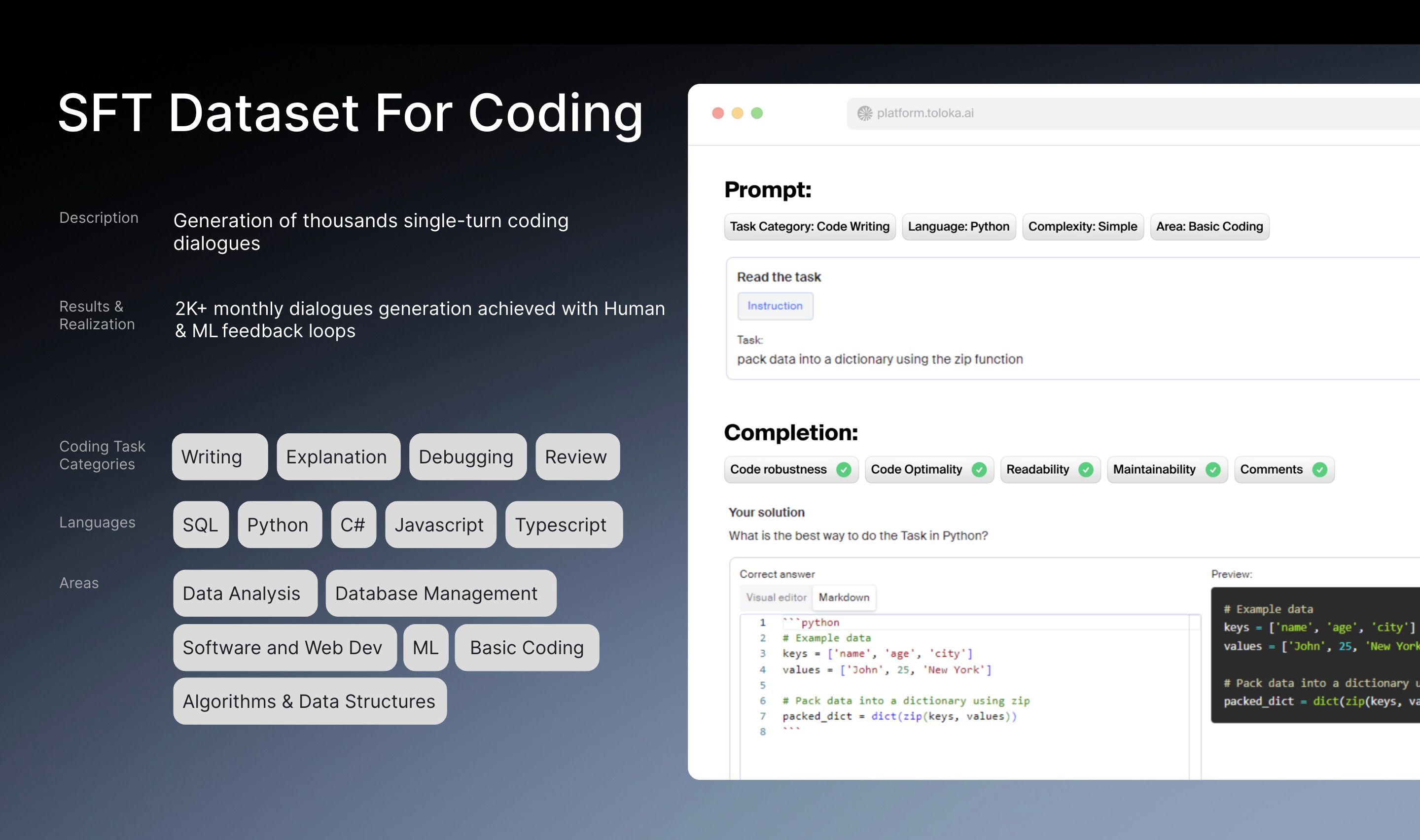
SFT dataset for coding domain
The challenge involved creating an SFT dataset covering various programming languages, including Python, SQL, Scala, Go, C, C++, R, and JavaScript. Toloka aimed to generate a significant number of high-quality question-answer pairs addressing different coding challenges within this domain.
The task was particularly challenging because it involved the work of highly qualified experts, coordination of their efforts, and had to be delivered within a given timeframe. Additionally, we had to focus on ensuring high quality throughout this project as it was crucial to craft prompts and prompt completions that fulfilled user requests, were accurate, and concise.
Pipeline for coding SFT dataset
To tackle the challenge, Toloka crafted a solution that combines human expertise with modern Machine Learning (ML) techniques in a data-gathering pipeline. We assembled a team of coding experts proficient in all necessary programming languages, serving as the foundation of the project with their primary responsibility being to maintain high data quality. Additionally, to assist human experts and speed up the process, we developed several ML algorithms that perform data extraction and automatic data checks. The constructed pipeline is shown in the schema below and each step will be further described in the next subsections of this article.
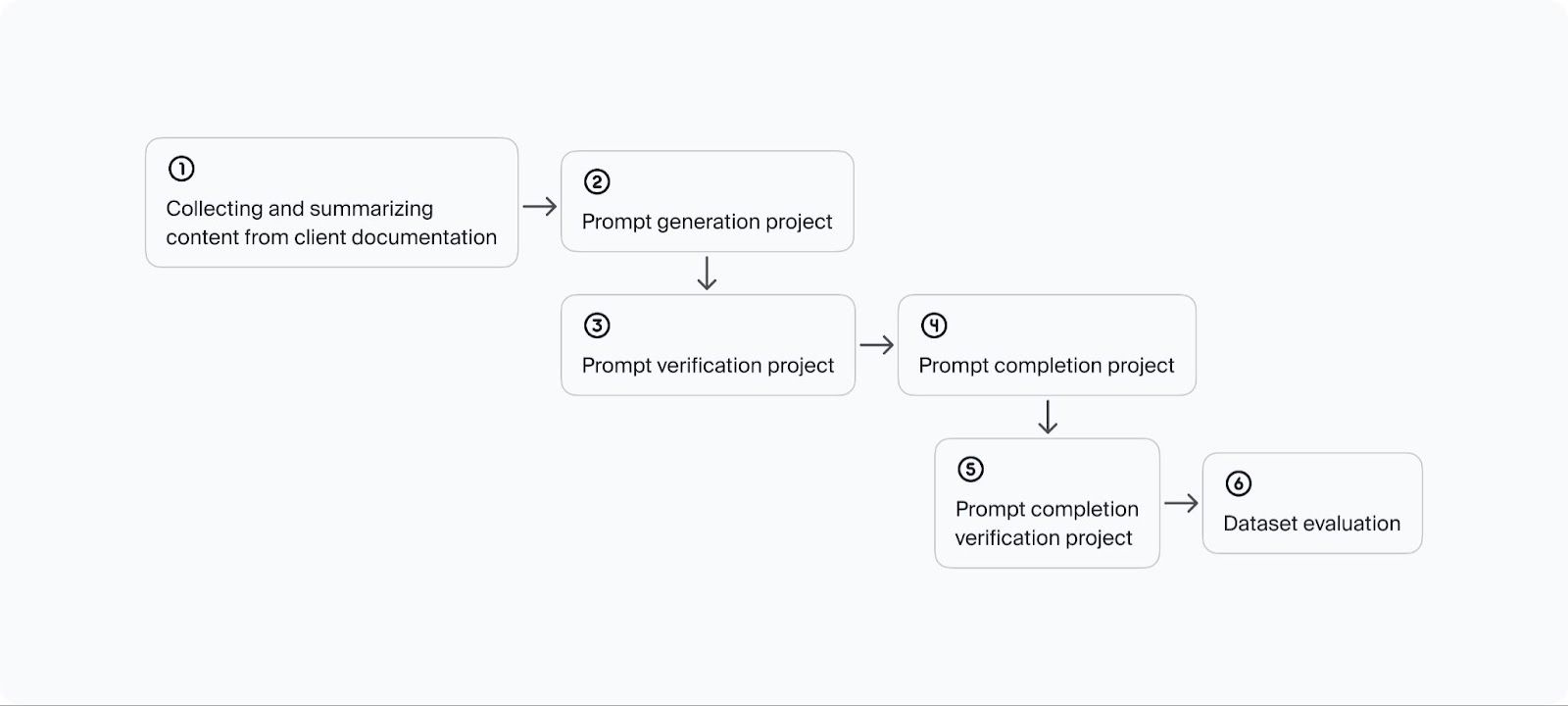
- Collecting and summarizing the context data from documentation
The initial step of the pipeline involves extracting information from clients’ documentation regarding the problems that LLM must be able to address. This stage automatically gathers details about each coding problem, such as context, keywords, programming language, category, and subcategory. These details are then utilized in the subsequent step to generate prompts effectively.
- Generating prompts with experts
In the second step, the extracted information is passed to a human coding expert. Their task is to create the actual prompt by following specific instructions and carefully considering the context and other relevant details. An example of such a task is illustrated in the screenshot below.
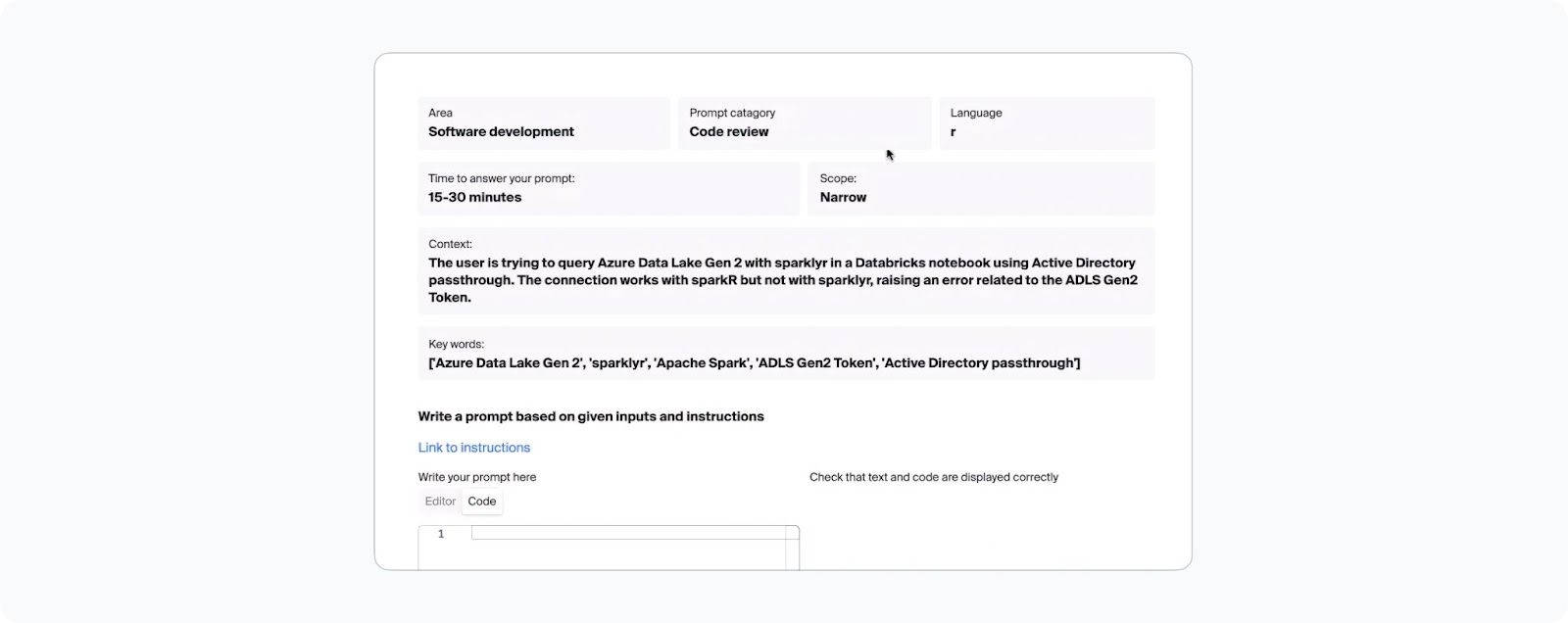
Prompt generation task
To support experts in generating prompts, we use open LLMs to automatically generate synthetic data across a range of topics, user cases, and scenarios. It gives them examples, they can follow and improve their creativity. Ultimately, this approach improves the efficiency of experts and enhances the diversity and quality of prompts collected during this phase.
- Verifying prompts
In the third step, the prompts crafted in the previous project are reviewed by a second line of coding experts and ML models. The models perform basic classification checks to confirm that the prompt corresponds to the chosen category, subdomain, and programming language. Meanwhile, human coding experts assess the prompt’s quality, suitability, and adherence to instructions, context, and provided details. Examples of some questions given to coding can be found in the screenshot below.
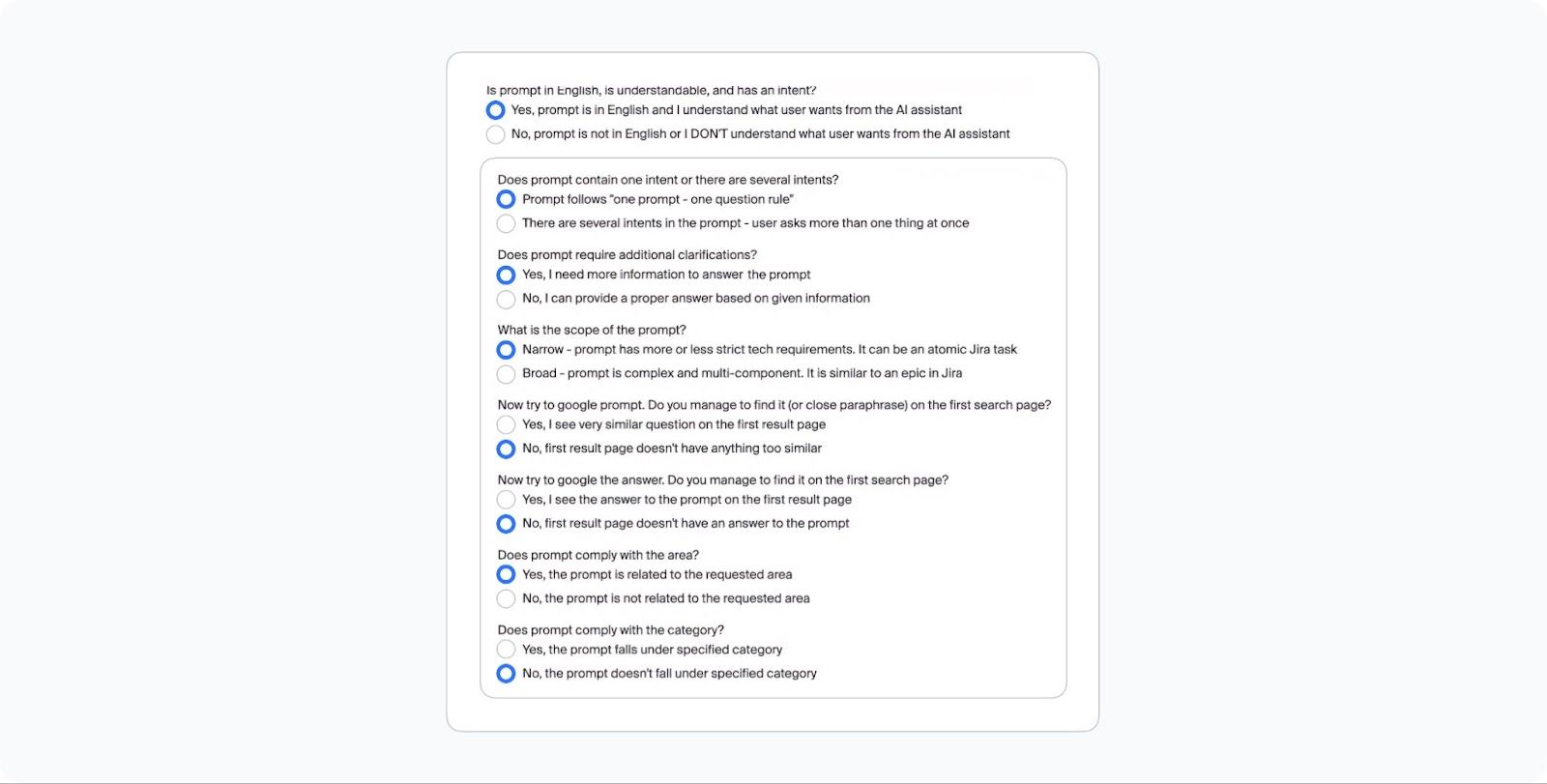
A subset of questions from the prompt verification task given to human coding experts assessing the prompt’s quality, suitability, and adherence to instructions, context, and provided details.
In our pipeline, the prompts that do not meet the required criteria are rejected and need to be rewritten whereas the accepted ones move on to the next step, where coding experts are tasked with writing completions.
- Writing completions with experts
The fourth step in our pipeline requires experts to follow carefully crafted instructions when writing answers to user queries. They must ensure that their completions fully address user requests and are truthful, elegant, and concise. Once an expert completes a response, it proceeds to the next step for further verification.
- Verifying completions with experts
The fifth step involves a second line of human coding experts verifying the completion. This ensures that the prompt completion is assessed by a different person from the one who wrote it. Once again, experts must answer detailed questions about the completion’s quality. Examples of these questions are provided in the screenshot below.
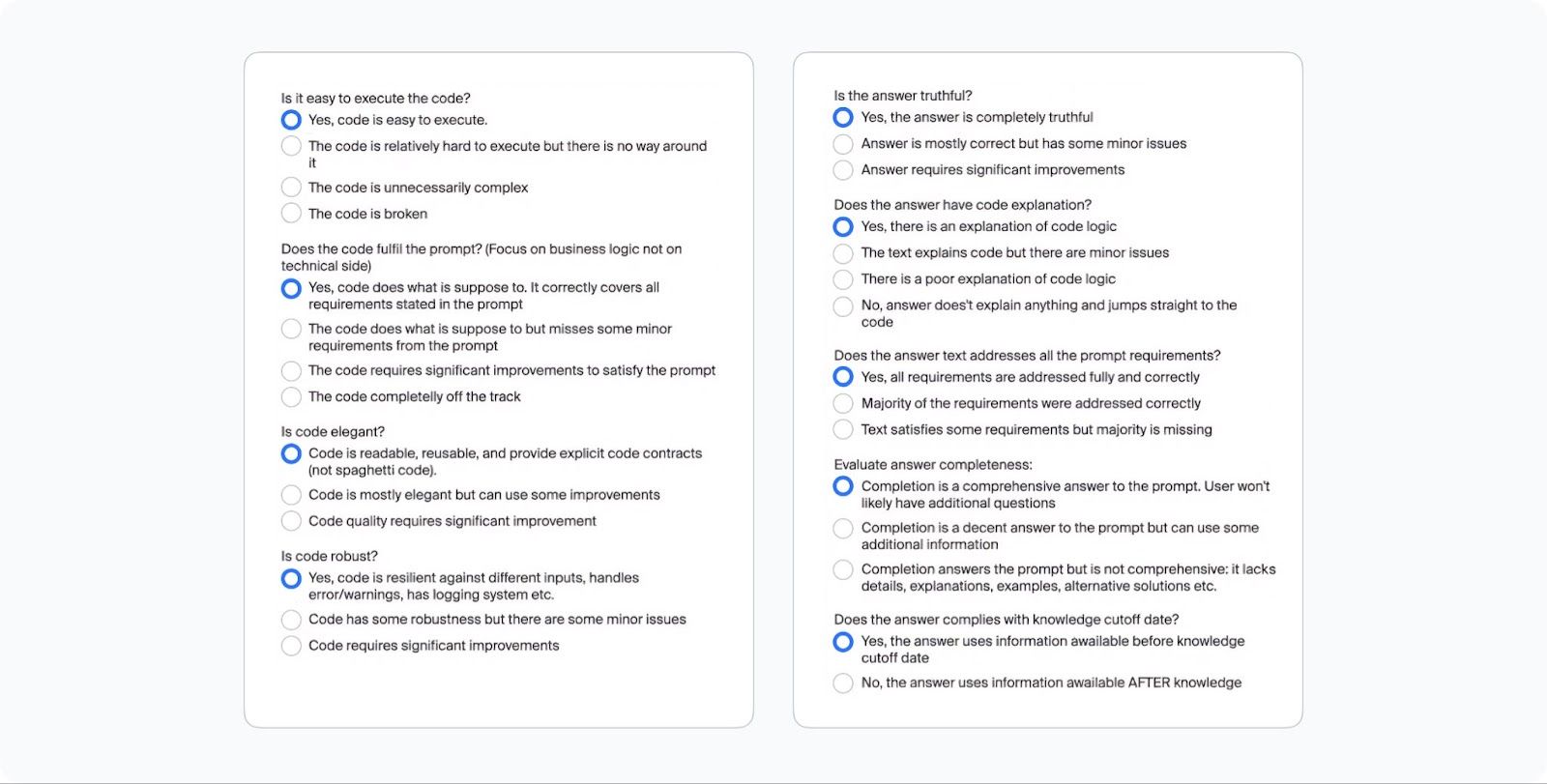
Prompt completion verification task
Similarly to a prompt verification project, if the completion’s quality does not meet the required standards, it is rejected and must be rewritten. Otherwise, it is accepted together with the corresponding question and becomes a new data point in the dataset.
- Evaluating the created dataset
This brings us to the final sixth step in the pipeline, where we run an evaluation of the dataset to assess its overall quality even before it is consumed by an LLM. For each data point in the dataset, we request different models such as GPT-3.5, LLama, and Mistral to complete the prompt, and then compare these answers to the responses given by our experts. This is done using both expert evaluation to ensure data quality, and automatic evaluation with GPT-4 to improve cost and scalability. In both scenarios, a decision maker (expert or a model) is presented with a side-by-side comparison of two answers, asked about preference. We collect the number of win rates against the previously mentioned models and a high number gives us confidence that the dataset will improve the LLM our client is developing.
In addition to ensuring data quality, we also examine the distribution of the dataset based on languages, technologies, and cases to ensure it aligns with the desired parameters before providing it to the client. Additionally, we perform checks to identify and remove any semantically similar samples. Only rigorously, checked datasets are delivered to the client. If any criteria are not met, we continue refining the dataset until all issues are resolved.
Summary
The above pipeline demonstrates how to structure an SFT data-gathering project by combining human expertise with ML solutions giving it an additional boost of efficiency and scalability. Collecting a domain-specific dataset poses unique challenges, necessitating a large pool of expert annotators and effective coordination of their activities. While we’ve applied this pipeline for coding we can easily adapt it to other niches. This includes different industries such as medicine, law, engineering, finance, pharmaceutical, and many more. We have experts in all of those fields and extensive experience in running data annotation AI projects.
If you are interested in gathering a dataset for a specific domain, feel free to reach out to us. We can build a custom solution for you similar to the pipeline outlined in this article.

Recent articles




Have a data labeling project?
