Chatfuel drives chatbot quality with Toloka Deep Evaluation

Subscribe to Toloka News
Subscribe to Toloka News
The challenge
The outcome
A leading no-code chatbot platform provider, Chatfuel powers over a billion conversations monthly for hundreds of businesses, including brands like Netflix and Adidas. Their conversational LLM-based chatbots automate business communication with consumers on Facebook Messenger, Instagram, WhatsApp, and websites, in roles from support to customer retention and upselling.
When you're putting a chatbot in charge of your sales funnel and customer support, you rely on exceptional quality. However, LLM-driven chatbots are prone to a couple of major problems:
- Giving the user false information, such as nonexistent products or invalid promo codes, which leads to customer frustration and more frequent intervention from human support agents.
- Using the wrong tone of voice or mistakenly recommending competitor products, which can impair the customer experience and harm brand perception.
Chatfuel aims to guarantee high-quality responses from their chatbots. Toloka provides a deep evaluation framework to get a clear picture of chatbot quality, an essential step to keep Chatfuel's customers satisfied and uphold the brand's reputation in today's digital communication landscape.
Toloka has been an invaluable partner in our pursuit of improving our AI-driven customer support solutions. Their expertise and collaboration have allowed us to understand the weak points within our GPT-based customer support bots, enabling us to address critical shortcomings and enhance the overall user experience. Toloka's insights and suggestions for refining our custom GPT model have also been instrumental in fine-tuning its performance and accuracy. Now, we are better equipped to provide more efficient and effective chatbots, making them an indispensable part of our journey towards AI excellence.
— Oleg Krasikov, Head of Product, Chatfuel
The challenge: Evaluating LLM quality in chatbot scenarios
The main goal of our evaluation was to benchmark the performance of Chatfuel's chatbot pipeline, powered by ChatGPT, against the current industry-leading compact open-source model, Mistral-7B-Instruct-v0.1.
The primary challenge was to develop a robust evaluation framework capable of adapting to Chatfuel's specific domain of support chatbots. We catered to a variety of chatbot scenarios, from managing open-ended customer conversations to offering precise answers from company knowledge bases.
The Toloka team adapted our deep evaluation framework to this domain and designed a flexible evaluation pipeline that will extend to a broader range of Chatfuel's chatbot applications in the future.

The solution: Tailored metrics for helpfulness, truthfulness, and tone of voice
In the initial stages of our evaluation, we considered a range of informative metrics, including Completeness, Conciseness, Operator Interaction, Text Quality, and First Response Resolution.
We further refined our metrics to focus on the overall success of Chatfuel’s support chatbot model. These three metrics were identified as most impactful in enhancing user satisfaction and ensuring effective communication:
- Helpfulness and Relevance measure the chatbots' ability to provide pertinent responses to user queries.
- Truthfulness ensures alignment with Chatfuel's knowledge base.
- Tone evaluates the chatbots' adherence to the brand voice or appropriate style.
Each metric was carefully assessed using a pointwise approach, allowing Chatfuel to make cross-metric comparisons and track absolute performance over time. Our flexible framework left room to enhance the sensitivity of the tests where necessary by adding a pairwise variation for each metric.
Chatfuel's production pipeline powered by ChatGPT was benchmarked against the Mistral-7B-Instruct model built in the RAG pipeline to gauge relative effectiveness compared to the open source model, which can be used by any third-party striving to build a chatbot using publicly available sources.
Helpfulness and Relevance
Approach: Assessed by human experts with backgrounds in customer support.
Methodology:
- Relevance: Evaluators analyze statements from chatbot responses and judge how well they address and resolve user queries. They label each statement with one of the following classes: relevant/partially relevant/irrelevant/neutral.
- Helpfulness: Next, evaluators check if the responses are directly useful and actionable in the context of the user's request.

Truthfulness
Approach: Also evaluated by specialized human experts.
Methodology: Evaluators examine whether the chatbot response statements are factually correct and in complete alignment with Chatfuel's established knowledge base.
Challenges: Truthfulness can be difficult to assess, especially in nuanced customer support scenarios. This metric requires evaluators with a high degree of precision and skill.
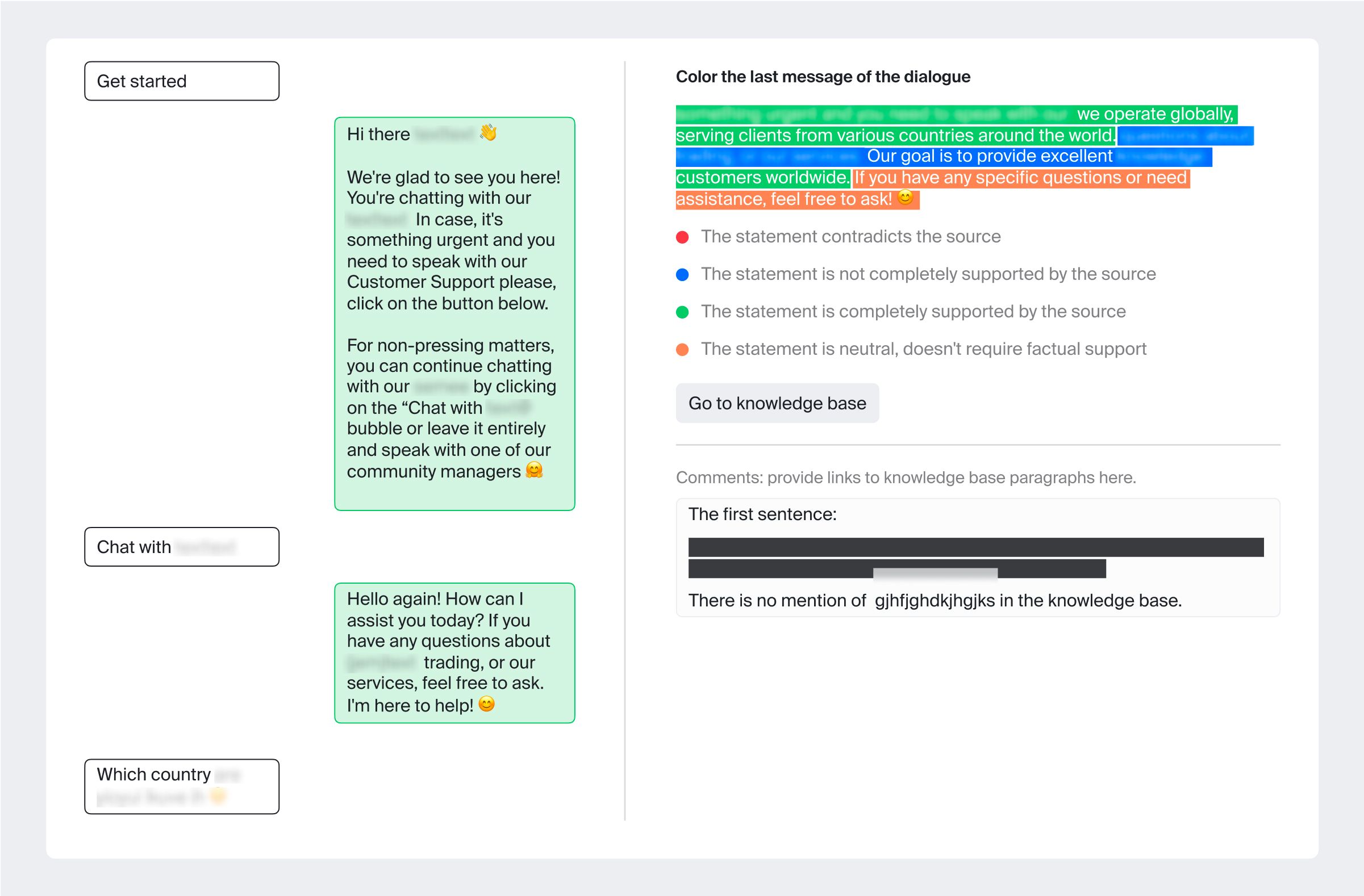
Tone
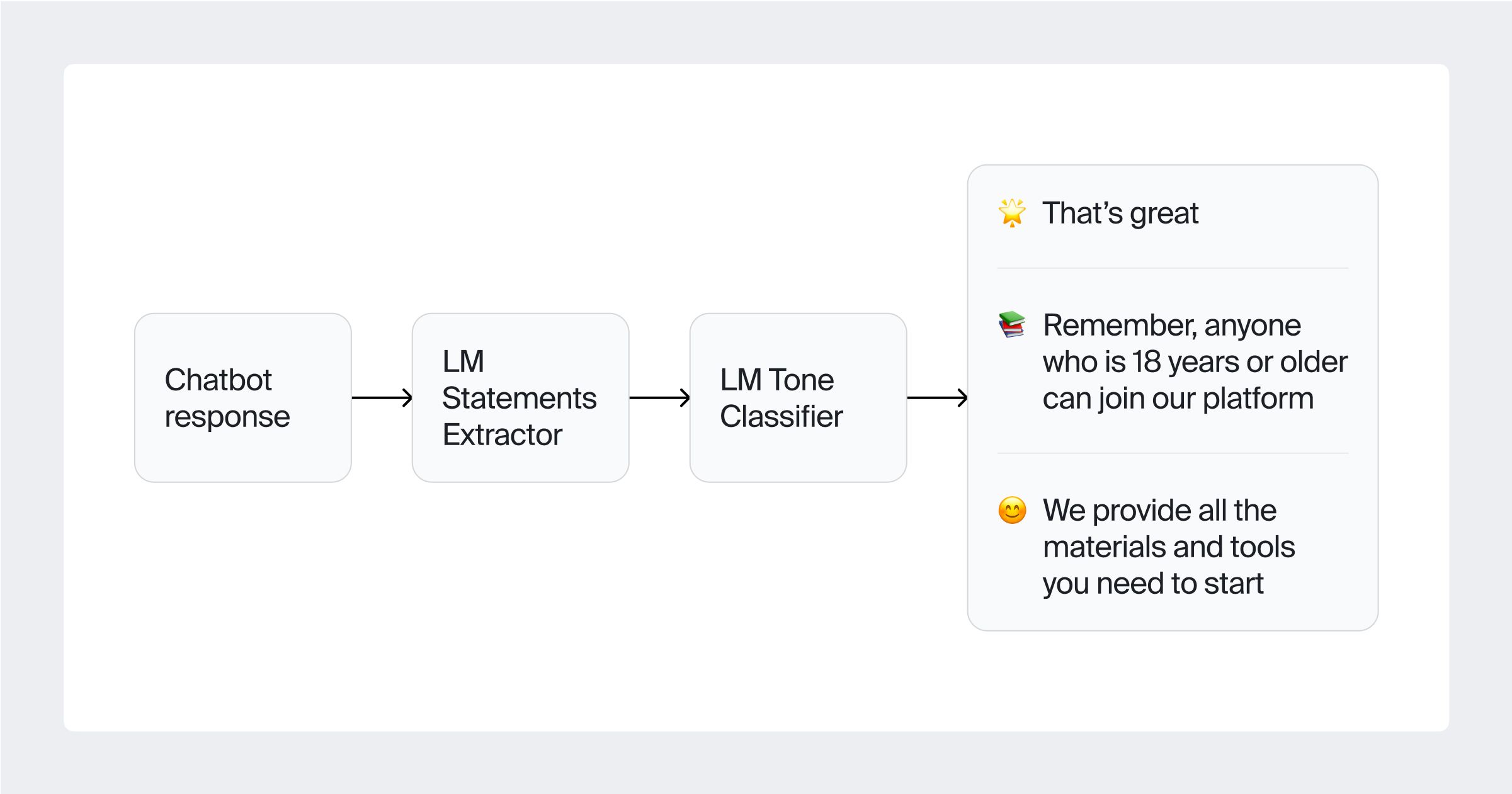
Approach: Streamlined classification via highlighting using state-of-the-art language models.
Methodology: Tone evaluation analyzes how well the chatbot's responses match the desired communicative style, be it formal, friendly, or otherwise. The tone should be consistent and appropriate to the context. We used the following tone labels:
- Formal (complete sentences, no contractions, sophisticated vocabulary)
- Friendly (casual language, contractions, colloquialisms)
- Moderate (a blend of formal and friendly, polite but not rigid)
- Enthusiastic (positive adjectives, exclamation points, emphasis with capital letters)
- Empathetic (understanding language, phrases showing concern)
- Instructive (direct guidance, steps outlined)
- Funny (wit, humor, subtle jokes)
- Inappropriate (offensive, toxic, insensitive language)
Challenges: To automate tone assessment, we carefully balanced quality and cost of the language model to maintain high evaluation standards without incurring excessive expenses.
Results and insights
Helpfulness and Relevance
Helpfulness
We used a paired assessment where evaluators directly compared output from Chatfuel's model and Mistral-7B-Instruct and chose the most helpful response for each query. Our evaluators showed a strong preference for the Chatfuel model (54.6% wins compared to 12.4% for Mistral-7B-Instruct).
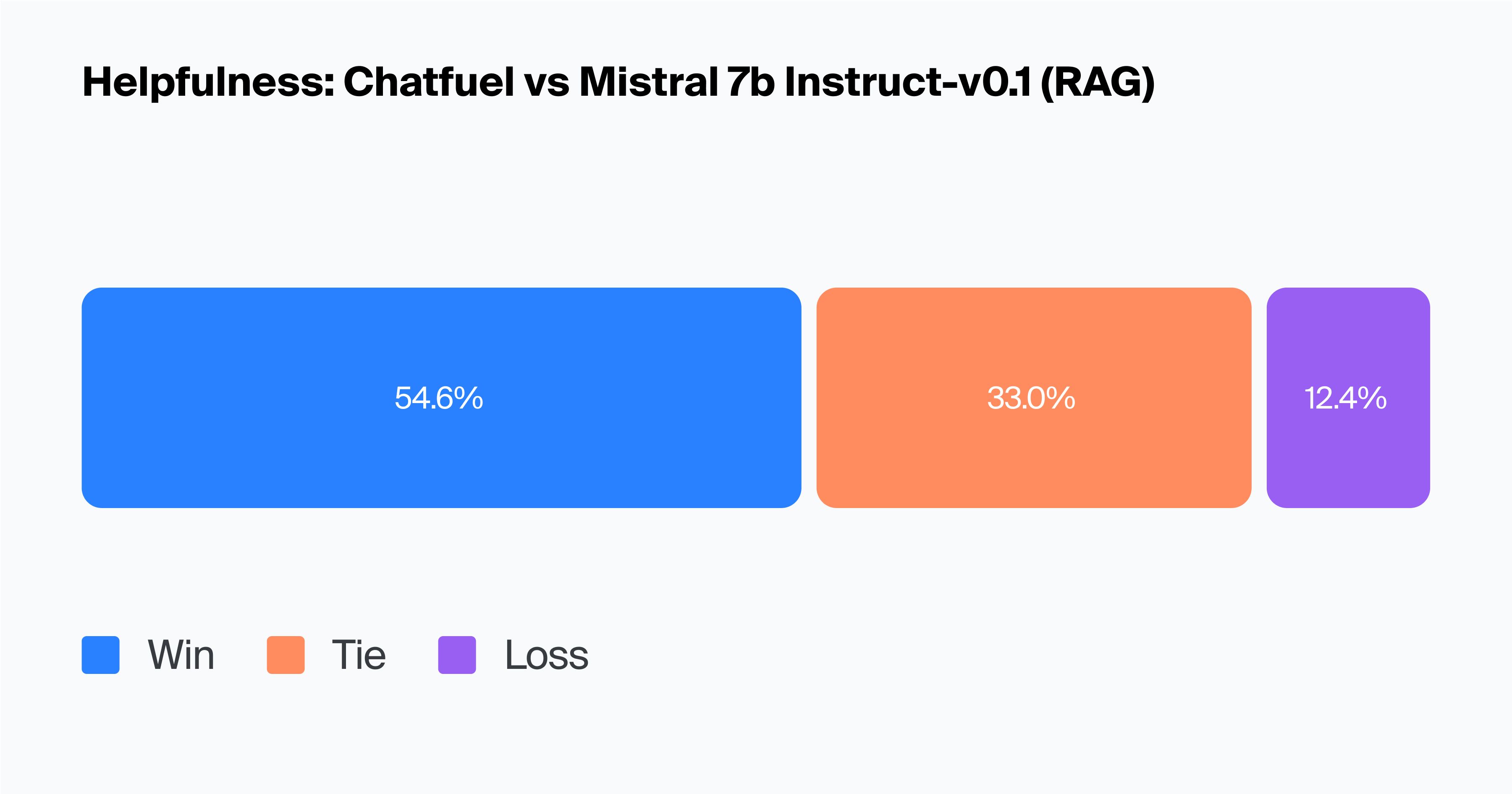
Bootstrap resampling confirmed the statistical significance of these results, indicating that Chatfuel's win rate in helpfulness is significantly higher than both the tie rate and the loss rate. This suggests the Chatfuel model is much more robust in terms of helpfulness compared to Mistral-7B-Instruct-v0.1.
Relevance
Chatfuel's model also performed better than Mistral-7B-Instruct on relevance, with a significantly higher percentage in the Relevant category and lower percentages in the Neutral, Partially Relevant and Irrelevant categories, proven with statistical tests. This suggests that Chatfuel's responses are more likely to directly answer the user's question.
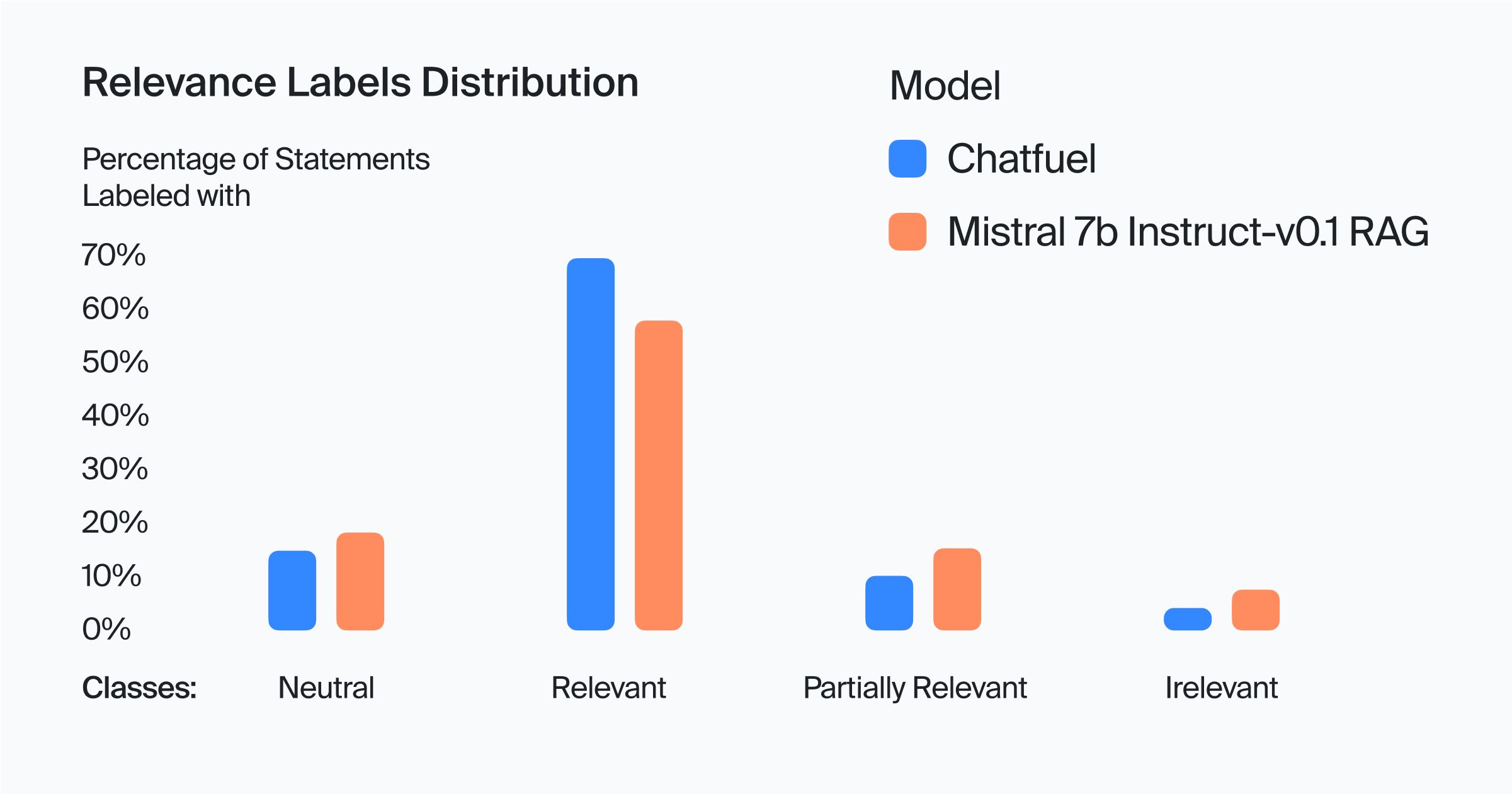
Chatfuel's higher percentage of Relevant statements, with significantly lower scores in Neutral, Partially Relevant, and Irrelevant categories, points to a consistently relevant response strategy.
Key takeaways
- The Chatfuel model outperforms Mistral-7B-Instruct-v0.1 in helpfulness, with a significant win rate. This points to its effectiveness in providing more user-oriented, actionable, and engaging responses.
- Chatfuel's higher relevance percentage underscores its capability to provide more accurate and pertinent answers to user queries, enhancing the overall user experience.
- The lower percentages in Neutral and Irrelevant categories for Chatfuel imply a reduction in ambiguous or off-topic responses, which is crucial for maintaining user engagement and trust in the accuracy of the information provided.
- It is very important to evaluate the helpfulness metric in combination with truthfulness, because often the answer is useful to the user, but does not meet our expectations set in the knowledge base at all. An example is when the model answers an out-of-domain question.
- The relevance and helpfulness of a response can vary greatly depending on the context of the conversation or the specific needs of the user. Therefore, it is crucial that evaluators are trained using detailed guidelines that clearly define what constitutes relevant, partially relevant, and irrelevant responses, reducing subjectivity.
Truthfulness
In our truthfulness evaluation of Chatfuel's model and the Mistral-7B-Instruct built in the RAG pipeline, we analyzed four categories: Supported, Neutral, Unsupported, and Contradicts. The results provide insightful comparisons between the two models.
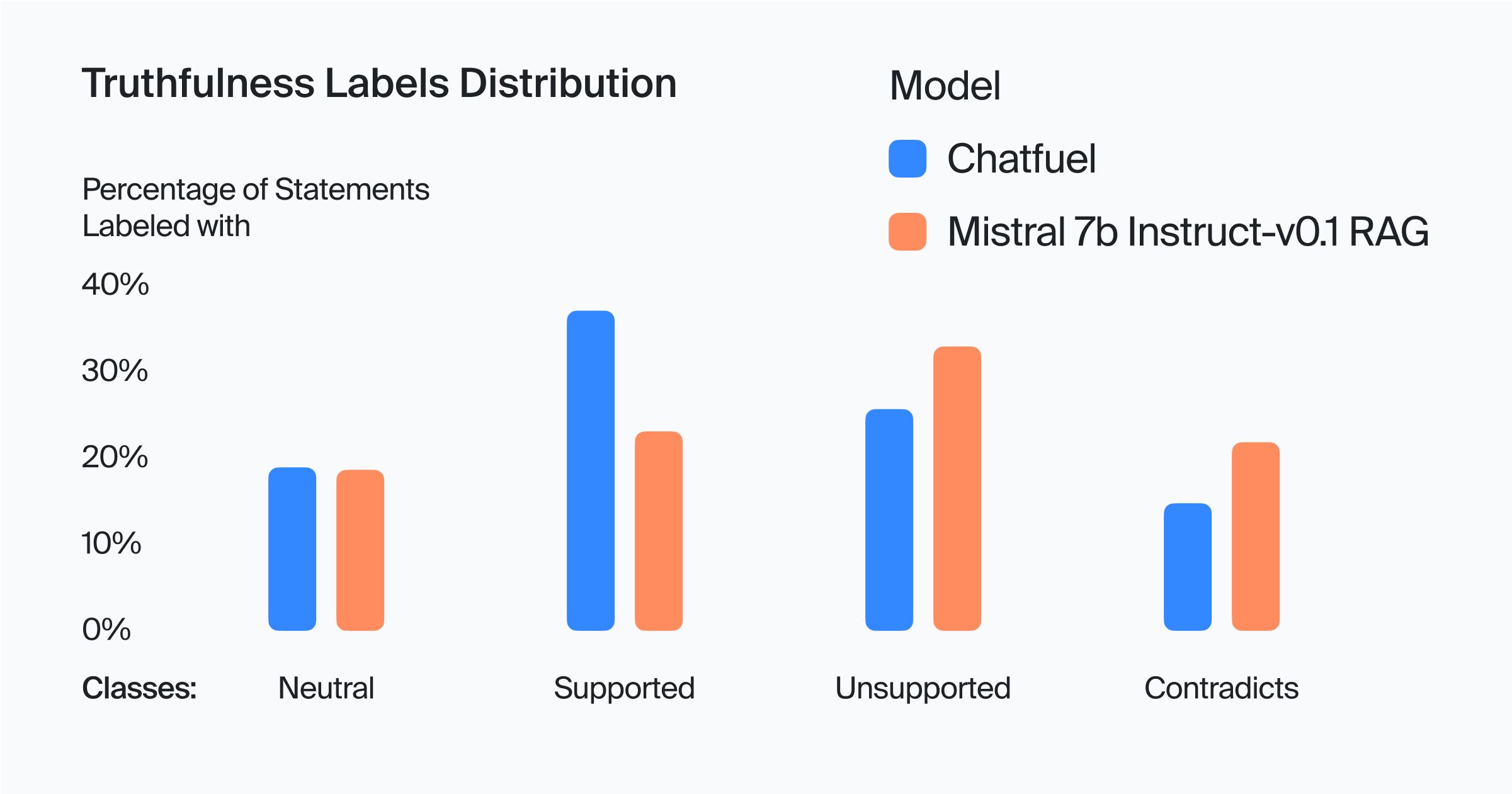
The points below summarize the bootstrap confidence intervals for the differences in response ratios between the Chatfuel model and the Mistral-7B-Instruct model, taking into account the paired origin of the data. These intervals help determine whether the observed differences in the performance metrics of the two models are statistically significant.
- "Neutral" Ratio: 🤝 Tie (No significant difference between Chatfuel and Mistral-7B-Instruct)
- "Supported" Ratio: ✅ Favoring Chatfuel (significantly higher than Mistral-7B-Instruct)
- "Unsupported" Ratio: ✅ Favoring Chatfuel (significantly lower than Mistral-7B-Instruct)
- "Contradicts" Ratio: ✅ Favoring Chatfuel (significantly lower than Mistral-7B-Instruct)
Key takeaways:
- The Chatfuel model demonstrated a significantly higher Supported ratio (38.43%) compared to Mistral-7B-Instruct (23.98%). This suggests Chatfuel's model is more effective in providing responses that align with the knowledge base.
- Chatfuel had a significantly lower Contradicts rate (15.27%) compared to Mistral-7B-Instruct (22.60%). This implies that Chatfuel's model is less likely to provide contradictory information.
- The Unsupported category was significantly higher in Mistral-7B-Instruct. This indicates a tendency of the model to venture into ambiguous or gray areas, raising concerns about the potential for inaccuracies.
- The data suggests that both models, particularly Mistral-7B-Instruct, may struggle in scenarios where the knowledge base is limited, leading to a higher rate of unsupported responses. This implies that there's room for improvement in how the models rely on and utilize facts from the knowledge base.
In summary, while the Chatfuel model shows a stronger alignment with the knowledge base in terms of support and fewer contradictions, both models exhibit challenges in dealing with unsupported information, indicating a need for more robust integration with and reliance on the knowledge base.
Tone
The tone distribution analysis for Chatfuel and Mistral provides valuable insights into the tone of voice employed by each model in their interactions.
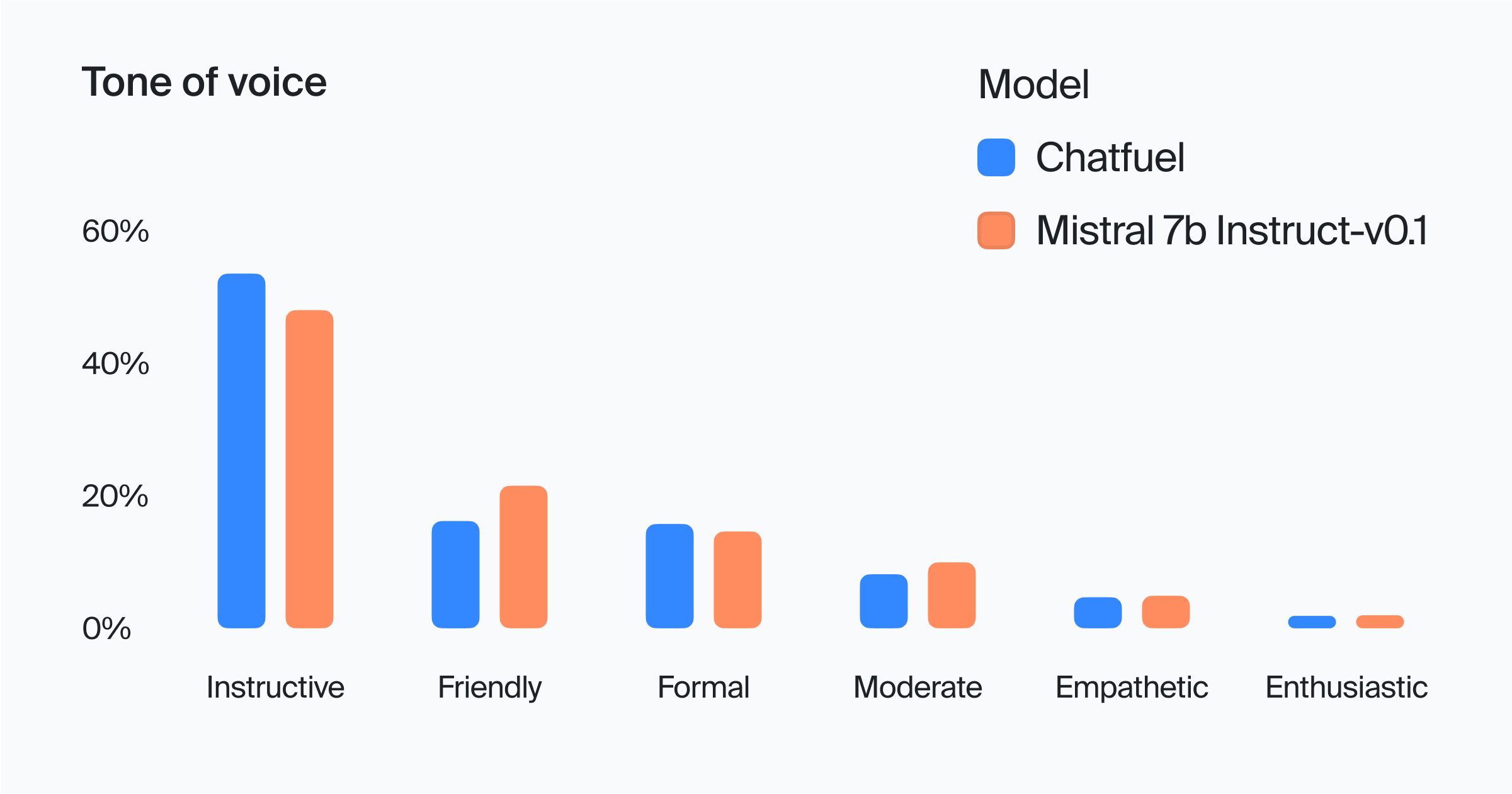
- Both Chatfuel and Mistral show a high prevalence of the Instructive tone, with Chatfuel slightly higher at 52.86% compared to Mistral's 47.32%.
- Chatfuel is more formal, with a Friendly tone at 16.26% and a Formal tone at 15.68%, whereas Mistral employs a more Friendly tone (21.50%) compared to its Formal tone (14.41%). This indicates that Mistral might be leaning towards a more personable and casual interaction style than Chatfuel.
In an innovative approach, a specialized n-gram language model was trained on annotated labels to analyze the tone sequences in responses from both Chatfuel and Mistral-7B-Instruct-v0.1 models. The analysis revealed distinct patterns illustrated in the figure below:
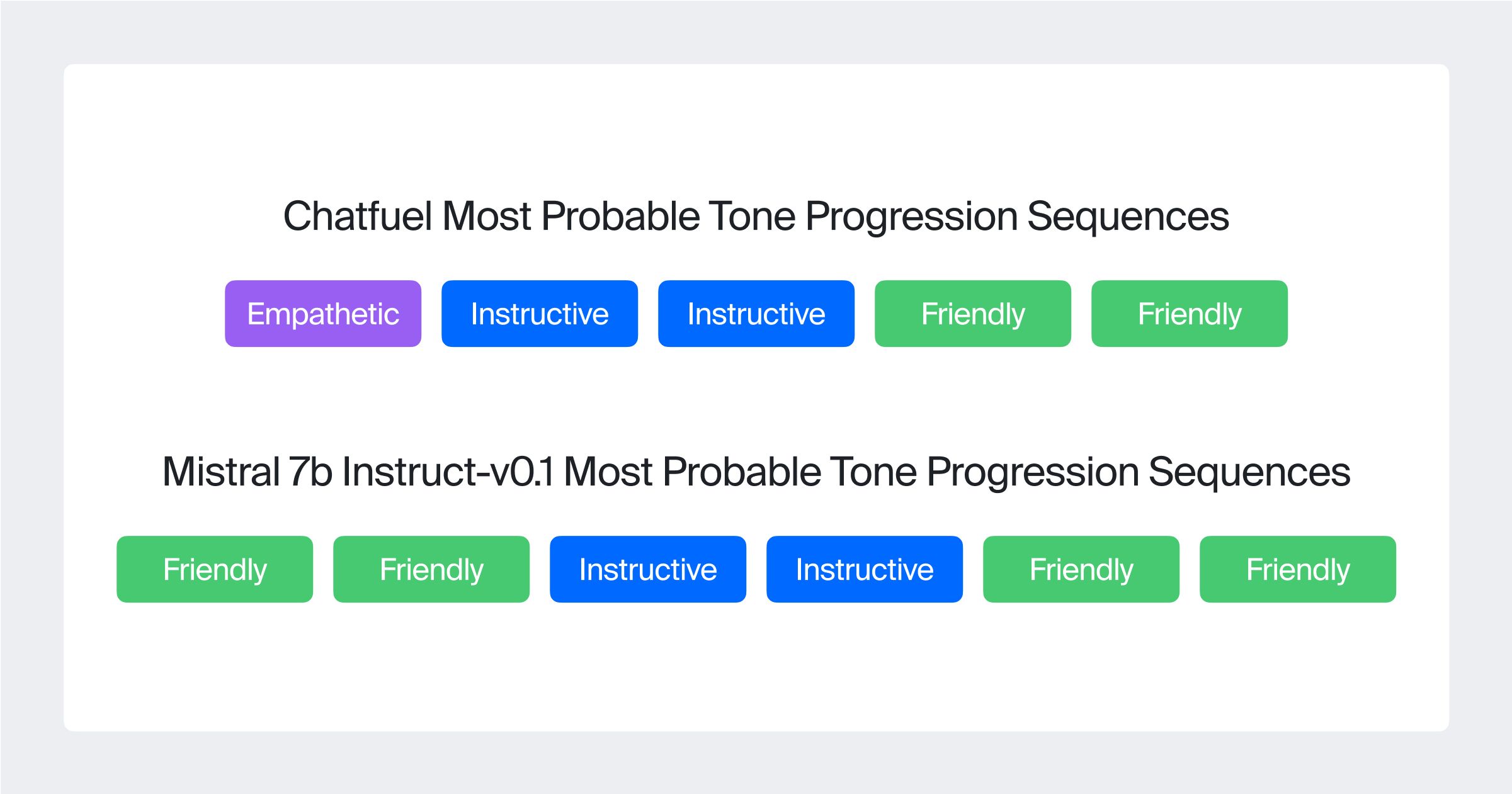
This difference highlights Chatfuel's tendency to start conversations with empathy before providing instruction, whereas Mistral frequently initiates interactions with a friendly tone, suggesting a more consistently personable approach throughout the conversation.
Key takeaways
The table below contrasts the predominant tones and interaction styles of the Chatfuel and Mistral chatbot models, highlighting their respective focuses in user engagement:
| Aspect | Chatfuel | Mistral |
|---|---|---|
| Primary Tone | Instructive 📘 and Formal 🎩 | Instructive 📘 and Friendly 😊 |
| Interaction Style | Starts with Empathy 🤗, then Clear guidance 🧭 | Consistently Friendly 😊, followed by Guidance 🧭 |
| Design Focus | Balances Empathy with Structured Directive Interactions 🏗️ | Prioritizes Personable Engagement, then Instructive Guidance 🌐 |
- Based on this information, Chatfuel can reinforce control over the model's voice tone in response, reflecting this in the prompt. For example, you can explicitly prohibit the model from giving formal answers if this contradicts the image of the client company.
- The current prompt and knowledge base implicitly force the model to respond in an instructive style with a clear intention to guide the user with the purpose of solving a task. This should be taken into account when building chatbots for other domains where an instructive tone may be unacceptable.
- The basic ChatGPT model used by Chatfuel is more inclined to empathy than its competitor Mistral-7B-Instruct-v0.1. The team should pay careful attention to this aspect when testing other models (new versions of GPT, Claude, and others), as the property of empathy can disappear when changing the base model if it is not embedded in the prompt.
- The tone analysis of the model provides a great opportunity for using information in the RLHF and RLAIF pipelines, providing the ability to obtain a model with a perfectly aligned voice tone.
The impact: An outstanding support chatbot experience
Toloka's deep evaluation focused on Helpfulness, Truthfulness, and Tone to get at the heart of model quality for Chatfuel's support chatbots. The results revealed that the Chatfuel model excels in providing relevant and empathetic responses to user requests.
Chatfuel gained valuable insights and benefits from the evaluation cycle:
- Superiority over open-source models: Our evaluation quantitatively affirmed the superiority of Chatfuel's pipeline over the industry-leading compact open-source model Mistral-7B-Instruct-v0.1, enabling them to focus on further enhancements.
- Data for reinforcement learning: The evaluation data can be utilized in RLHF/RLAIF pipelines, offering a unique way to improve the model's quality.
- Improvement of knowledge base and prompts: Insights from the evaluation can help refine the knowledge base and prompts, reducing unsupported responses in unfamiliar domains.
- Brand perception and consistent tone: The evaluation findings regarding the chatbot's tone can guide Chatfuel in shaping their client companies' brand perception by modifying the base model, prompts, or knowledge base.
The Chatfuel team can adapt the same evaluation framework to enhance their e-commerce chatbots and other products as needed. Most importantly, Chatfuel customers can be confident that they are getting an outstanding support chatbot experience.
Learn more about Toloka Deep Evaluation:
Learn more
Recent articles




Have a data labeling project?
